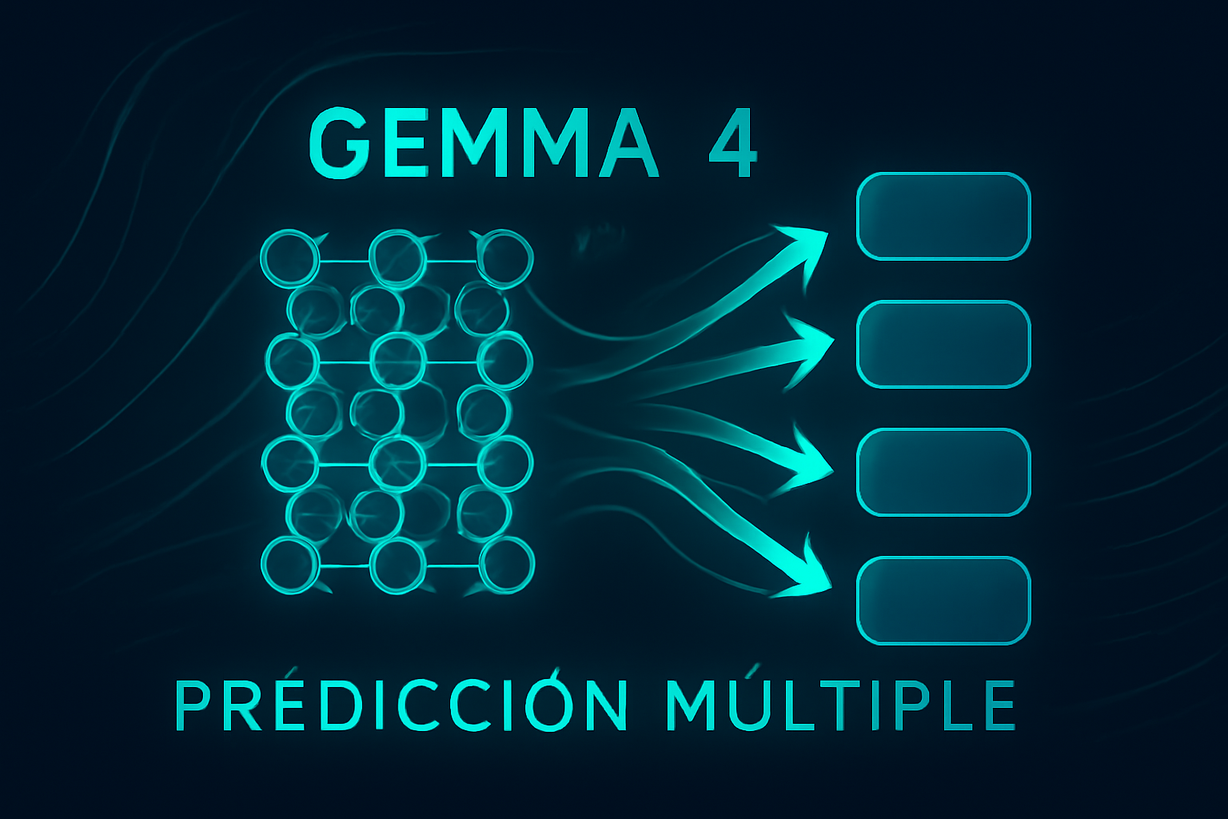
La técnica de decodificación especulativa en modelos de lenguaje, como Gemma 4, permite generar múltiples tokens simultáneamente, mejorando la eficiencia y reduciendo la latencia en comparación con los métodos tradicionales. Esto se logra al desacoplar la generación de tokens de su verificación, utilizando un modelo ligero para predecir secuencias que luego son validadas por un modelo más pesado. Esta innovación es crucial para optimizar el rendimiento en aplicaciones que requieren respuestas rápidas, como asistentes de codificación y agentes autónomos.
blog.google
Tecnologa
Optimización de Modelos de Lenguaje: Decodificación Especulativa para Respuestas Rápidas